1. 강화 학습의 개념
강화학습이란 상태(state), 행동(action), 보상(reward)로 구성되어 있다.
강화학습은 순차적인 의사결정 문제에서 누적 보상을 최대화하기 위해 시행착오를 거쳐서 상황에 따른 행동정책을 학습한다. 에이전트와 환경으로 정의하면 에이전트는 학습의 주체, 의사 결정자, 행동의 주체이며 환경은 에이전트를 제외한 모든 것이다. 에이전트가 St라는 상태에서 At라는 행동을 하면 환경이 이를 관측하고 Rt+1의 보상과 다음 상태 St+1를 에이전트에 전달한다.

2. 마르코프 확률
마르코프 확률은 강화학습에 있어 선행되어야하는 개념이다.
Markov Property(마르코프 확률)는 미래의 상태는 현재의 상태에 영향을 받으며 과거의 상태는 영향을 받지 않는다는 이론이다. 현재에 대한 조건부로 과거와 미래가 서로 독립인 확률 과정이다.
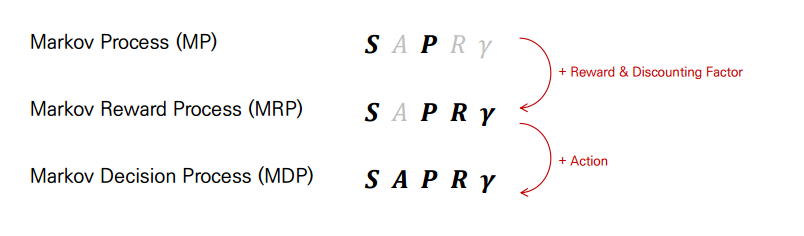
Markov Process(MP)
확률 과정중에 하나로 Markov Property 상태인 확률 과정을 말한다. 시간이 진행함에 따라 상태가 확률적으로 변화하는 과정이다. 랜덤 변수(random variable)가 분포되어있는 시간 간격(time interval)마다 값을 생성해내는데 현재상태가 이전 상태에만 영향을 받는 확률이 Markov Process이다. t 시점에 어떤 사건이 발생활 확률은 오직 t - 1에서만 발생 할 수 있다는 이론이다.
Markov Reward Process(MRP)
MP에 Reward 개념을 주가한 것이다. MP는 각 state별 transition의 확률만 주어지고 state에서 다음 state로 가는 것이 얼마나 가치가 있는지 알 수 없기때문에 도입된 개념이 Reward이다.
Markov Decision Process(MDP)
MDP는 MRP에 action과 policy의 개념이 추가된 것이다. agent가 하는 policy를 선택하고 action에 대해서 value 판단을 수행할 수 있다. Markov Property를 갖는 전이 확률을 이용해 의사결정을 하는 것을 MDP라고 하는데 에이전트와 환경의 상호작용을 상태, 행동, 보상의 확률로 정의한 것이 상태전이확률이다. 정확한 상태 전이 확률은 St에서 St+1로 이동할 확률을 말한다. 상태 전이 확률을 model이라고 부르며 여기서 model-based methods와 model-free methods가 등장한다. 따라서 Model-based 강화학습은 MDP에 대한 모든 정보를 알 때 이를 이용하여 정책을 평가 및 개선해나가는 과정이고 Model-Free 강화학습은 MDP를 알 수 없을 때 정책을 평가 및 개선해나가는 과정이다.
3. 강화학습의 종류
강화학습의 종류는 다름과 같다. 분류 기준에 따라 다르게 분류되어 아래는 진화형/마르코프 분류의 그림이다.

모델 유무에 따른 분류는 다음과 같다.
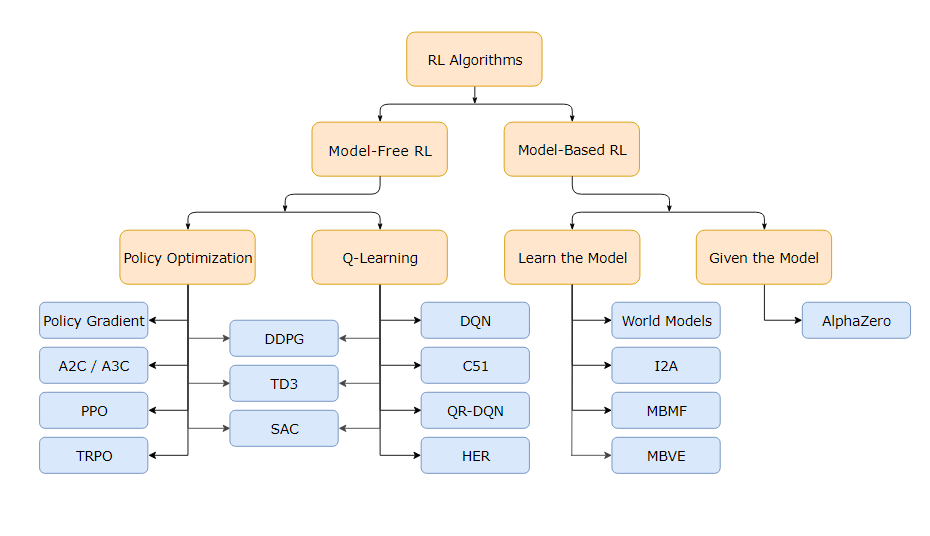
Model-based Algorithm는 환경에 대해 알고 있고 행동에 따른 환경의 변화를 알고있는 알고리즘이고, Model-free Algorithm은 행동에 따른 보상을 최대로 하는 정책을 찾고자하는 알고리즘으로 탐사를 바탕으로 정책을 점차 학습시켜야한다.
3-1. Q-Learning이란
Q-Learning은 모델 없이 학습하는 강화학습의 알고리즘으로 목표는 유한한 마르코프 결정과정에서 특정상황에서 특정행동을 하는 최적의 Policy를 배우는 것이다. 현재 상태를 시작으로 모든 연속적인 단계를 거쳤을 때 전체 보상의 예측 값을 극대화한다. Q는 행동의 보상에 대한 quality를 상징한다.
어떤 상태에서 어떤 행동을 수행했을 때 행동의 가치를 계산하는 Q-Value를 사용한다. 자세한 개념은 이곳을 참조한다.
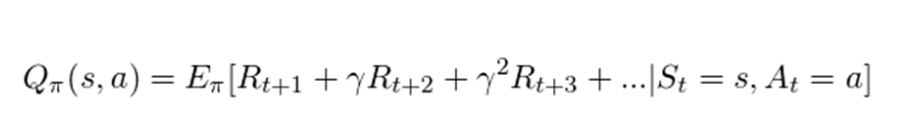
3-2. SARSA
Q-Learning와 SARSA의 중요한 차이점은 SARSA가 정책 알고리즘이라는 것이다.
Q-Learning은 E-greedy(Epsilon) Algorithm를 따른다. 그리디 알고리즘은 미래를 생각하지 않고 각 단계에서 가장 최선의 선택을 하는 알고리즘이다. 각 단계에서 최선의 선택을 한 것이 전체적으로 최선이길 바란다. 학습하면서 얻은 가치 함수 중 가장 큰 값을 따라간다. 이는 테스트 단계에서는 활용되기 좋지만 미래의 다른 최상의 결과가 존재하는 것을 고려하지 않았기 때문에 이를 개선시킨 전략이 E-greedy(Epsilon) Algorithm이다.
탐색과 착취(가장 많은 보상을 가져다주는 행동)사이에서 무작위 선택을 해 균형을 맞춘다. 아래의 그림을 통해 더 자세하게 이해할 수 있다.

SARSA는 그리디 알고리즘이 아닌 현재의 정책이 수행하는 행동을 바탕으로 Q 값을 학습한다는 의미를 담고 있다.
3-3. DQN
Q-Learning은 일반성이 부족하기 때문에 신경망을 도입해 2차원 배열을 없앤것이 DQN이다.
'tmp' 카테고리의 다른 글
| Prototype Pollution (0) | 2023.02.08 |
|---|---|
| DDE(Dynamic Data Exchange)와 CSV Injection (0) | 2023.02.07 |
| [AI] 기초 개념 학습 #1(ML 종류) (0) | 2023.01.30 |
| YAML (0) | 2023.01.28 |
| 직렬화(Serialization)와 역직렬화(Deserialization) (0) | 2023.01.20 |
